14.2. Analysis of list operators¶
Lists can be faster than vectors when inserting or erasing at a position
that is already represented by an iterator.
They are not generally faster for every operation, however.
We know push_back() is amortized \(O(1)\) for a vector,
and we know that a vector does not have a push_front() operation.
Inserting at the beginning of a vector requires shifting all of its
existing elements to make room.
The table below shows the asymptotic complexity
of some common list operations.
Note that many are constant time when the required iterator is already available.
Note that many list operations such as insert and erase take an iterator
as a parameter.
Once you have the iterator, these operations take constant time,
however, getting the correct iterator can often take \(O(n)\),
if you have not saved the iterator from a previous operation.
Operation |
Complexity |
|---|---|
assignment = |
O(n + m), where n and m are the two list sizes |
push_front() |
O(1) |
pop_front() |
O(1) |
push_back() |
O(1) |
pop_back() |
O(1) |
erase(i) |
O(1) |
insert(i, item) |
O(1) |
insert(i, b, e) |
O(n) in the inserted range |
splice(whole list) |
O(1) |
begin() |
O(1) |
end() |
O(1) |
size() |
O(n) before C++11; O(1) since C++11 |
Here i is an iterator identifying the position. The constant-time
erase and insert entries describe operations after that iterator
has been found. The whole-list splice overload transfers existing nodes
without copying their values.
Both vector and list support an insert() method.
There are multiple overloads for each and both support inserting
a range of elements at an arbitrary location in the container.
The following code shows the code for
inserting a range into a container.
template<class Container>
void test_insert(Container& data, const Container& new_data){
data.insert(data.begin(), new_data.begin(), new_data.end());
}
The test_insert code inserts the range at the
beginning of the current data set.
This situation should benefit the linked list and handicap the vector.
This is one of the classic situations where linked lists are said to
outperform vectors.
Let's insert chunks of data onto the front of both a list and a vector.
The following code shows what happens when an int
is stored in the containers.
In this example, we take increasingly large containers and insert increasingly large containers to their fronts.
Each iteration creates containers with an initial size. The test function then inserts a second container of equal size at position 0.
1#include <chrono>
2#include <iostream>
3#include <iomanip>
4#include <list>
5#include <vector>
6
7using std::list;
8using std::vector;
9
10template<class Container>
11void test_insert(Container& data, const Container& other){
12 data.insert(data.begin(), other.begin(), other.end());
13}
14
15
16int main(){
17 using std::cout;
18 using clock = std::chrono::steady_clock;
19 using msec_t = std::chrono::duration<double, std::milli>;
20
21 cout << std::setw(6) << "size\t"
22 << std::setw(8) << "vector::insert\t"
23 << std::setw(8) << "list::insert\n";
24
25 for(int size = 10'000; size < 100'001; size += 10'000) {
26 vector<int> vector_data (size);
27 vector<int> new_vector_data (size);
28 vector_data.reserve(size * 2);
29 auto begin = clock::now();
30 test_insert(vector_data, new_vector_data);
31 auto end = clock::now();
32 msec_t elapsed_1 = end - begin;
33
34 list<int> list_data (size);
35 list<int> new_list_data (size);
36 auto begin2 = clock::now();
37 test_insert(list_data, new_list_data);
38 auto end2 = clock::now();
39 msec_t elapsed_2 = end2 - begin2;
40
41 cout << std::setprecision(6) << std::fixed
42 << size << '\t'
43 << std::setw(8) << elapsed_1.count() << '\t'
44 << std::setw(8) << elapsed_2.count() << '\n';
45 }
46 return 0;
47}
Both list and vector have linear complexity for this form of insert. The list must create nodes for the inserted range. The vector must also move its existing elements after the insertion point. This example reserves enough vector capacity to avoid measuring a possible reallocation, so the comparison focuses on moving elements versus allocating list nodes.
But it's not even close.
The embedded example intentionally stops at 100,000 so it can run within
the textbook compiler time and memory limits.
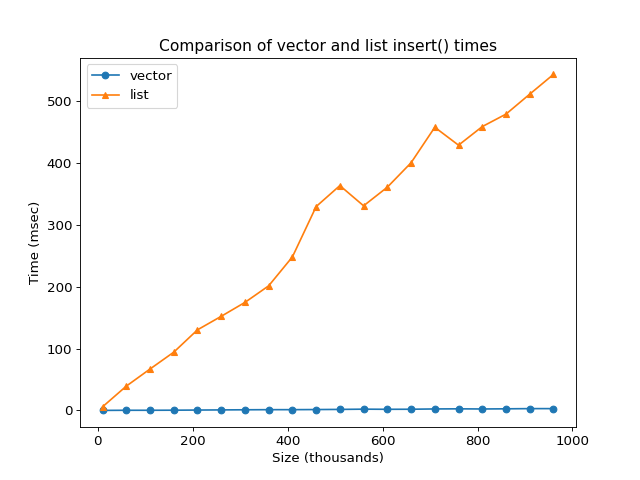
The graph below was generated separately, offline, with a longer version of
this benchmark and a loop starting at 10,000 and increasing by 50,000
until it reached 1,000,000.
Therefore, its final measured point is 960,000.
Try This!
The online compiler is limited in both memory and time allowed.
Run this example on your own computer with larger values and compare.
It may not look like it, but both of these insertions are \(O(n)\) in
the size of the range inserted.
In this particular run, for small types like int, the vector was about
150 times faster than the linked list. The exact ratio depends on the compiler,
library, hardware, allocator, and system load.
How can this be?
In short: memory.
Recall that a vector stores its elements contiguously. A linked list typically allocates each node separately.
Computers have a feature called cache memory and it turns out the vector is able to exploit this resource better than a list.
What is Cache Memory?
Modern processors use a hierarchy of storage, including registers, cache, and main memory. Cache is smaller and faster than main memory, and the processor automatically moves data between these levels in cache lines. When nearby data is reused, contiguous storage gives the processor a better chance of finding it in cache instead of waiting for main memory.
Cache is relatively small and is managed by hardware. Its replacement policy is not necessarily simply "least frequently used."
Although both commonly use dynamically allocated storage, because the vector is a single chunk, the CPU has a better chance of keeping more of the data in cache memory.
In addition, it turns out that modern CPUs are just very good at creating, copying, and moving chunks of memory.
There are situations where a list does outperform vector, we just have to work harder to see it.
To force our test containers to work harder, instead of a vector of int,
we create a type that is a simple array wrapper:
// a bloated class to make insert work harder
template<int N>
struct junk {
std::array<unsigned char, N> data;
};
Other than the change in type stored in the vector, nothing is different from the int
timing example.
vector<junk<2048>> vector_data (size);
1#include <array>
2#include <chrono>
3#include <iostream>
4#include <iomanip>
5#include <list>
6#include <vector>
7
8using std::list;
9using std::vector;
10
11template<class Container>
12void test_insert(Container& data, const Container& other){
13 data.insert(data.begin(), other.begin(), other.end());
14}
15
16// a bloated class to make insert work harder
17template<int N>
18struct junk {
19 std::array<unsigned char, N> data;
20};
21
22
23int main(){
24 using std::cout;
25 using clock = std::chrono::steady_clock;
26 using msec_t = std::chrono::duration<double, std::milli>;
27
28 cout << std::setw(6) << "size\t"
29 << std::setw(8) << "vector::insert\t"
30 << std::setw(8) << "list::insert\n";
31
32 constexpr int JUNK_SIZE = 2048;
33
34 for(int size = 1'000; size < 10'001; size += 1'000) {
35 vector<junk<JUNK_SIZE>> vector_data (size);
36 vector<junk<JUNK_SIZE>> new_vector_data (size);
37 vector_data.reserve(size * 2);
38 auto begin = clock::now();
39 test_insert(vector_data, new_vector_data);
40 auto end = clock::now();
41 msec_t elapsed_1 = end - begin;
42
43 list<junk<JUNK_SIZE>> list_data (size);
44 list<junk<JUNK_SIZE>> new_list_data (size);
45 auto begin2 = clock::now();
46 test_insert(list_data, new_list_data);
47 auto end2 = clock::now();
48 msec_t elapsed_2 = end2 - begin2;
49
50 cout << std::setprecision(6) << std::fixed
51 << size << '\t'
52 << std::setw(8) << elapsed_1.count() << '\t'
53 << std::setw(8) << elapsed_2.count() << '\n';
54 }
55 return 0;
56}
A change in data type stored in the vector produces different results.
The online compiler is limited in both memory and time allowed.
The JUNK_SIZE value is measured in bytes, so 2048 is 2 KiB per element.
That value was roughly the break-even point on the compiler used for the JOBE example.
The graph below was generated separately, offline, with JUNK_SIZE set to
8192, or 8 KiB per element.
Run this example on your own computer with larger values and compare.
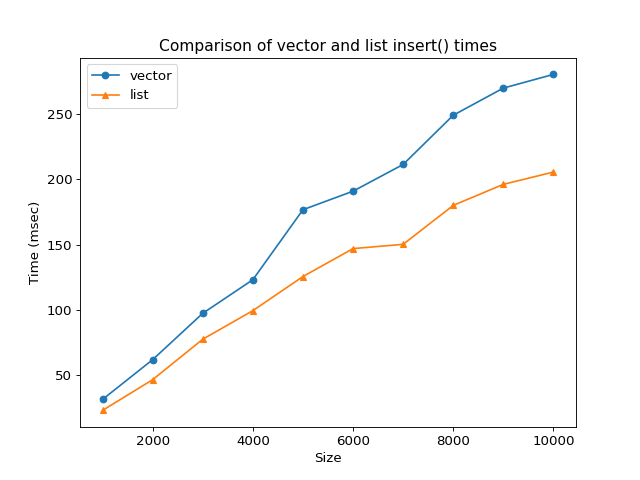
The sheer size of the data in each vector element increases the likelihood of a cache miss. In this case, the data is too large to fit much, if anything, in cache memory. The CPU fails to find it in cache, so it must retrieve it from RAM every time.
Both the vector and list are clearly \(O(n)\) and the list is outperforming the vector.
Try This!
What other situations might a list outperform a vector. Try some of the following with data types of different sizes:
Reversing data
Sorting data
Filling or constructing data
Removing data
More to Explore